清华姚班校友马腾宇,发布了他的首个多模态嵌入模型:「多模态检索」实现SOTA
清华姚班校友马腾宇和他的团队,推出了自创业以来的首个多模态嵌入模型 voyage-multimodal-3,而且发布即“SOTA”。
据介绍,在对 3 个多模态检索任务(共 20 个数据集)进行评估时,voyage-multimodal-3 比第二名平均高出了 19.63% 的检索准确率。这是为包含丰富视觉和文本的文档提供无缝 RAG 和语义搜索的重要进展。
去年 11 月,已为斯坦福大学助理教授的马腾宇,正式宣布了他的大模型创业项目 Voyage-AI,旨在提供 SOTA 嵌入模型,为企业的智能检索提供超级动力,推动检索增强生成(RAG)和可信赖的大语言模型(LLM)应用的发展。
据 Voyage-AI 官网显示,他们的学术顾问十分豪华,包括斯坦福大学首位红杉讲席教授李飞飞、斯坦福大学教授 Christopher Manning 和斯坦福大学副教授 Christopher Ré 等。9 月,Voyage-AI 完成了 2000 万美元 A 轮融资,总融资额达到 2800 万美元。

据介绍,与现有的多模态嵌入模型不同,voyage-multimodal-3 能够对交错文本和图像进行矢量化处理,并从 PDF、幻灯片、表格、数字等截图中捕捉关键视觉特征,而无需进行复杂的文档解析。
voyage-multimodal-3 支持文本和内容丰富的图像,如文本截图、数字、表格、PDF、幻灯片等。由此产生的矢量可捕捉关键的文本和视觉特征,如字体大小、文本位置、空白等。这消除了基于启发式的文档解析的需要,因为当布局复杂或穿插数字和照片时,启发式文档解析往往难以保证准确性。与处理单一文本或图片输入的现有多模态嵌入模型不同,voyage-multimodal-3 允许交错文本和图片,以实现最大的灵活性。
voyage-multimodal-3 的架构类似于视觉语言 transformers。这使得它与现有的多模态嵌入模型显著不同,包括但不限于 OpenAI CLIP large (clip-vit-large-patch14-336) 和 Cohere multimodal v3 (embed-multimodal-v3.0))。
在对 20 个多模态检索数据集和 34 个文本检索数据集进行的一组评估中,voyage-multimodal-3:
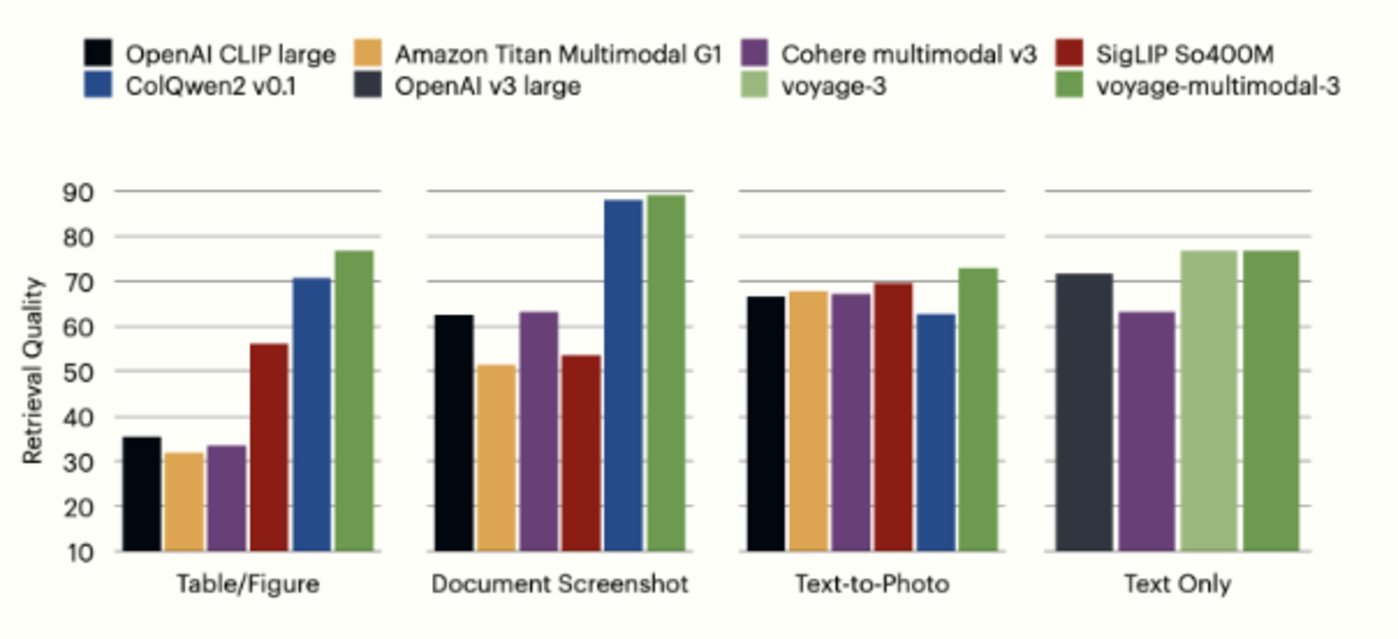
在表格/图表检索方面,平均分别比 OpenAI CLIP large 和 Cohere multimodal v3 高出 41.44%(提高 2.1 倍)和 43.37%(提高 2.2 倍);在文档截图检索方面,分别比 OpenAI CLIP large 和 Cohere multimodal v3 高出 26.54% 和 25.84%;在文本到图片检索方面,分别比 OpenAI CLIP large 和 Cohere multimodal v3 高出 6.55% 和 5.86%。
在纯文本数据集方面,分别比 OpenAI v3 large 和 Cohere multimodal/English1 v3 高出 5.13% 和 13.70%。
支持交错文本和图像
所有现有的常用多模态嵌入模型(如 Amazon Titan Multimodal G1、Google Vertex AI multimodal 和 Cohere multimodal v3)都基于 OpenAI 的 CLIP,其通过独立网络处理不同模态的数据。换句话说,图像必须通过视觉塔(vision tower)进行矢量化,而文本必须通过文本塔(text tower)进行矢量化,无法处理交错数据。
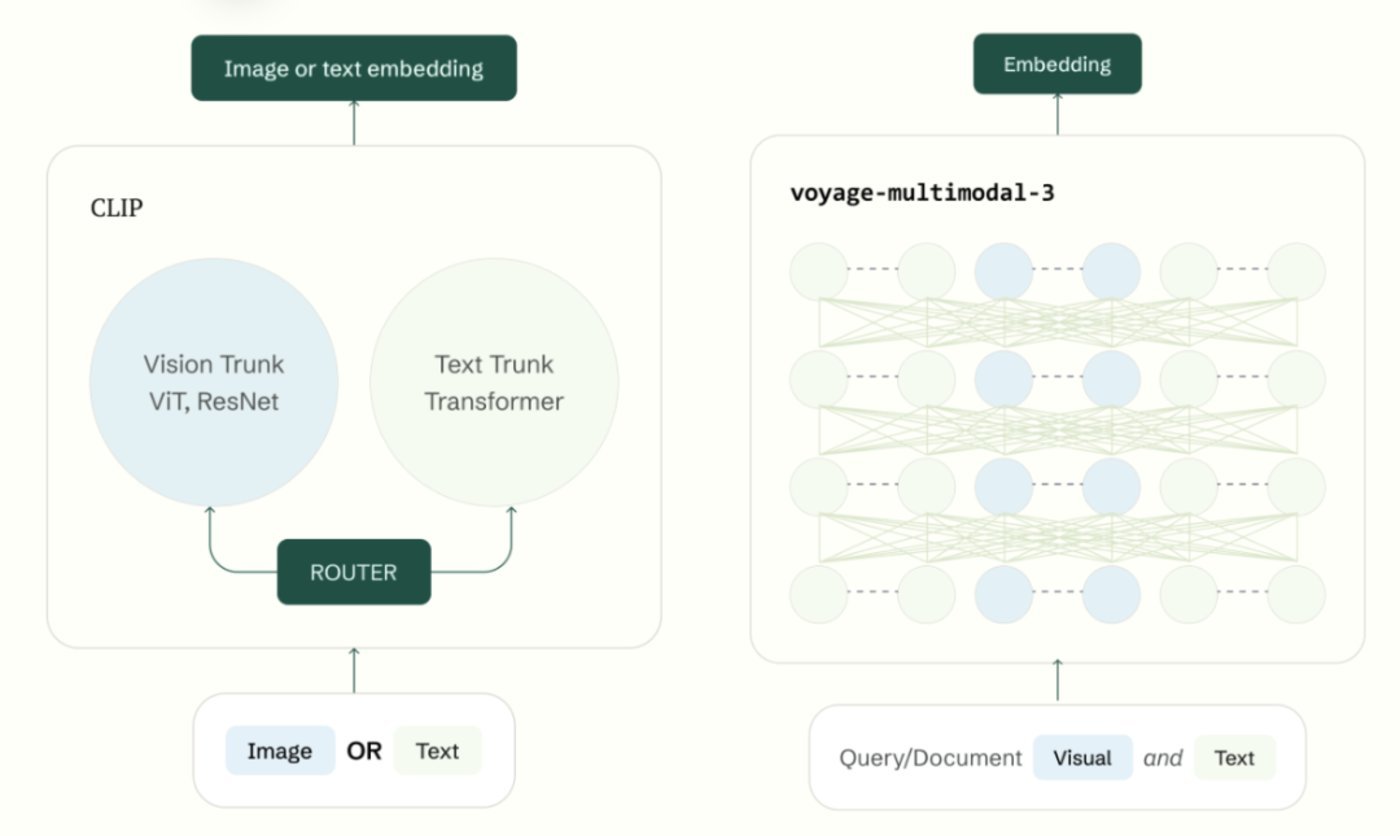
相反,voyage-multimodal-3 在同一个 transformer 编码器中直接对两种模态的数据进行矢量化,确保文本和视觉特征都被视为统一表征的一部分,而不是截然不同的组件。这模仿了最新视觉语言模型的架构,只是用于矢量化而非生成。因此,交错文本和图像、文档截图、具有复杂布局的 PDF 文件、带注释的图像等都能以保留视觉信息和文本信息之间上下文关系的方式进行矢量化。
利用截图进行混合模态搜索
由于模态差距(modality gap)这一现象,所有类似 CLIP 的模型在混合模态搜索方面都表现不佳。如下图所示,与“第七十七届国会成员,我向你们致辞......”片段最接近的向量不是其截图,而是其他文本。这导致搜索结果偏向于相同模态的条目;换句话说,在嵌入空间中,文本向量将更接近无关文本,而不是相关图片。

为了从数量上说明这个问题,他们进行了一项涉及混合模态数据的实验。他们创建了两套内容相同的 PyTorch 文档:一套是纯文本(字符串),另一套是屏幕截图。通过将基于文本的文档子集与剩余子集的屏幕截图相结合,他们创建了一系列混合模态数据集。每个数据集代表不同比例的文本和屏幕截图,屏幕截图的比例从 0% 到 100% 不等。然后,他们在这些数据集上评估了各种多模态模型的检索准确性,报告了每个模型在不同截图比例下的归一化折算累积增益(NDCG@10)。
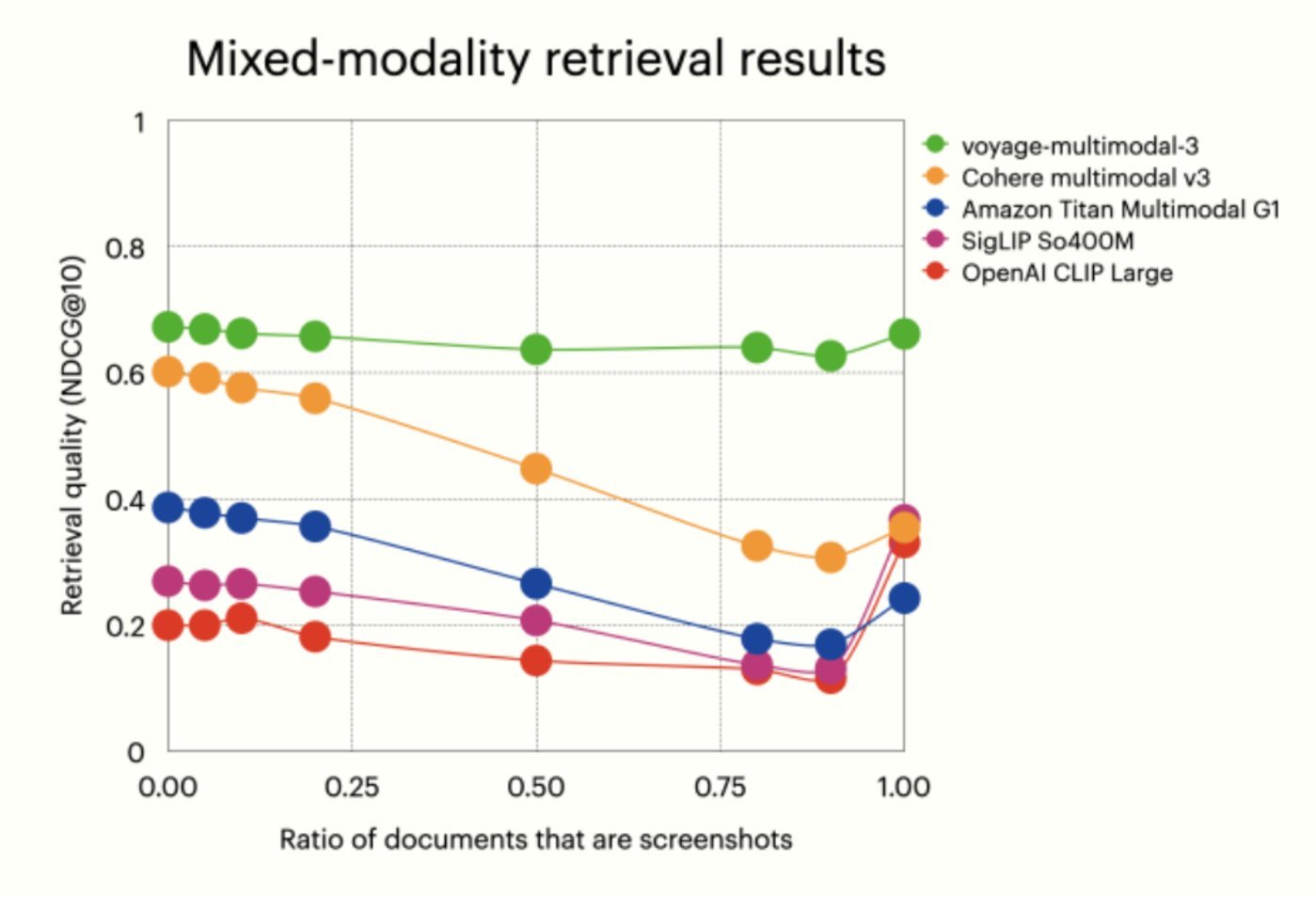
如上图所示,当屏幕截图的比例增加到 90% 时,基于 CLIP 的模型的检索质量就会下降,这凸显了受模态影响的检索偏差。
相比之下,voyage-multimodal-3 不仅在所有比例下都表现更好,而且在所有情况下几乎没有性能下降,这表明矢量真正捕捉到了截图中包含的语义内容。
有了 voyage-multimodal-3,我们就不再需要屏幕解析模型、布局分析或任何其他复杂的文本提取管道;我们可以轻松地将包含纯文本文档和非结构化数据(如 PDF/幻灯片/网页等)的知识库矢量化。屏幕截图就是你所需要的一切。
详细评估结果
数据集。他们在 20 个多模态数据集上对 voyage-multimodal-3 进行了评估,这些数据集涵盖三个不同的任务:表格/图表检索、文档截图检索和文本到图片检索。他们还在一个标准文本检索任务中对 voyage-multimodal-3 进行了评估,该任务涵盖 6 个领域(法律、金融、对话、代码、网络和技术)的 34 个数据集。
在所有数据集中,查询都是文本,而文档可以是图、照片、文本、文档截图或这些内容的组合。对于每项任务,他们都使用之前表现最好的模型作为基准。除了任务名称,他们还在下表中提供了每个任务的相应说明和使用的数据集:
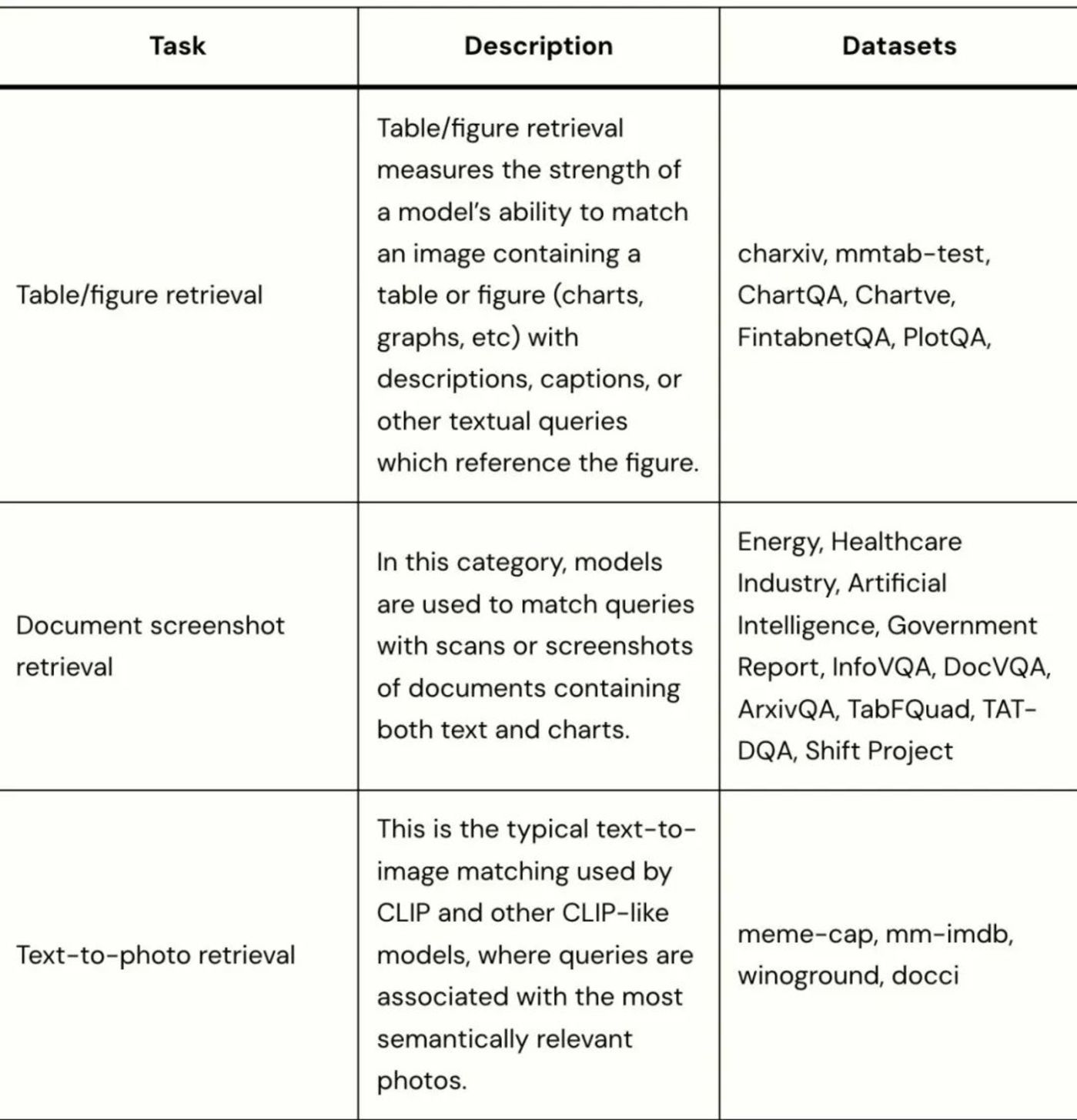

请注意,标准文本检索任务包括用于评估 voyage-3 和 voyage-3-lite 的所有数据集,长上下文和多语言数据集除外。
模型。对于三个多模态任务,他们将 voyage-multimodal-3 与四个可供选择的多模态嵌入模型进行了评估:OpenAI CLIP large(clip-vit-large-patch14-336)、Amazon Titan Multimodal Embeddings G1(amazon.titan-embed-image-v1)、Cohere multimodal v3(embed-multimodal-v3.0)和 SigLIP So400M(siglip-so400m-patch14-384)。他们还评估了 ColQwen2 v0.1(colqwen-v0.1),这是一种后期交互模型,可为每篇文档输出多个嵌入。
对于标准文本检索任务,他们评估了 voyage-multimodal-3 以及 OpenAI v3 large (text-embeddings-3-large)、Cohere multimodal/English1 v3 和 voyage-3。
指标。给定一个查询,他们按余弦相似度检索前 10 个结果,并报告 NDCG@10。
结果
多模态检索。如下图所示,voyage-multimodal-3 的性能分别比 OpenAI CLIP large、Amazon Titan Multimodal G1、Cohere multimodal v3、SigLIP So400M 和 ColQwen2 v0.1 高出:
在表格/图表检索上:41.44%、45.00%、43.37%、20.66% 和 6.14%;
在文档截图检索上:26.54%、37.68%、25.84%、35.62% 和 0.98%;
在标准文本检索上:6.55%、5.16%、5.86%、3.42% 和 10.34%。
如下图所示,voyage-multimodal-3 的性能分别比 OpenAI v3 large 和 Cohere multimodal/English1 v3 高出 5.13% 和 13.70%。voyage-multimodal-3 的性能比 voyage-3 高出 0.05%,因此两者在纯文本文档的检索准确率方面不相上下。